
How to Investigate Wikipedia: Our Process
How to Investigate Wikipedia: Our Process
Wikipedia celebrates its 20th anniversary this month. This blog post, the second of two, looks at how open source investigators can conduct research on Wikipedia.

This is the second of a two-part series on Wikipedia. The first part, "Inauthentic Editing," was published on January 7, 2021.
Wikipedia makes investigations simple. Unlike most platforms, Wikipedia goes out of its way to be open and transparent: revision histories, user actions, traffic analytics, and even some user IP addresses are all public information. Because anyone can edit Wikipedia, they rely on openness to protect against unwanted behavior — be it petty vandalism or agenda-driven reframing.
In the course of researching an edit war, we developed a toolkit of approaches that anyone can use to conduct their own investigations into inauthentic editing on Wikipedia. These approaches range from manual signals — “what to look for” style advice — to fully automated scrapers that can help surface suspicious pages. As is the case for many domains of open source investigation, we found that the most effective approach is to supplement manual investigation with automated tools. The tools are helpful for surfacing interesting pages, but cannot piece together the details of a coordinated “attack” — there, human intuition is key.
In this post we 1) identify attributes of pages that may indicate inauthentic editing, 2) provide an overview of free resources to analyze Wikipedia pages, and 3) introduce an open source notebook for automatically surfacing Wikipedia pages worthy of deeper scrutiny, with proof of concept evidence.
What to Look For
In general, there are two main targets when investigating Wikipedia: pages (also called articles) and users (also called editors). In general, we found that investigations tended to start with pages that looked suspicious, which then led us to look into the histories of the users who contributed to that page.
When looking at pages, we found that the followings signs were the most reliable indicators of inauthentic activity (signals with an asterisk are assessed by our automated script):
-
Too much content relative to notability.* Writing a Wikipedia article takes time, so the effort invested in a page is generally proportional to that page’s importance. When a page is extensive but the subject is barely notable, find out who did the bulk of the writing (see tips on users below), then investigate those users. A page’s traffic statistics are a good proxy for notability.
-
High levels of edit activity relative to notability.* There are 1.9 edits per second on Wikipedia; that works out to a little less than one edit per page per month. If a page has a significantly higher level of activity, it’s worth looking into why. It’s possible you’ve found an edit war (but it might be lame).
-
Controversy moved from introduction to body. The first paragraph of a Wikipedia article is the most important; it’s what Google shows in its knowledge panels, and might be the only content an impatient reader will see. When a short page mentions controversies but there is no reference to them in the opening paragraph, check if they were moved.
-
Pages that look like resumes. This is a real problem on Wikipedia. Biographical Wikipedia pages and resumes are very different, but sometimes inexperienced editors will model a page on a resume—bullet points and all. We found that new Wikipedia editors often have ulterior motivations when creating pages—that motivation may be the reason why they joined Wikipedia in the first place—so always investigate further when you encounter a novice-looking page (especially if there is a long “awards and honors” section).
-
Pages with many edits from one or a few users.* If the vast majority of a page’s edits come from a small number of users over an extended period of time, something may be amiss. While it’s common for editors to have subject matter expertise (and therefore be highly active in some networks of pages) and/or take “responsibility” for pages they created, over-active editors are cause for further investigation.
-
Overdependence on a few sources. Sometimes, when few independent sources are available about a subject, motivated editors will try to stretch them as far as possible to create the illusion of notability or consensus. Be wary when you see a long page that cites the same source dozens of times, especially when that source is a campaign website. (Wikipedia’s guidelines require that everything be cited to a source independent from the subject, but things can slip through the cracks.)
We found that some other seemingly-useful techniques were often dead ends and didn’t yield much useful information. For example, trying to find text copy-pasted from elsewhere on the internet usually didn’t reveal anything useful: the Wikipedia community is quite good at detecting plagiarism, but it is also inevitable that some text will slip through. (Plagiarism may simply be the sign of a lazy editor, not a malicious one.)
When looking at users, we found the most useful information was available on users’ talk pages, which serve as a forum for public correspondence between the Wikipedia community and a user. There, you can see whether a user is involved in any controversy. Sometimes, a user’s main page (where they introduce themselves ) will be empty but their talk page (where other users talk to them ) will be highly revealing. If a suspicious user has an innocuous-looking talk page, check archived versions of that page; the user may have blanked their page to hide earlier warnings. We found that it was usually difficult to tie Wikipedia editors to real-world identities (or even other online identities), but looking at editors’ IP addresses can still yield useful information.
Techniques and Tools
There are dozens of free online tools available that are helpful when investigating Wikipedia, but sometimes Wikipedia itself is the most useful tool. Here is an overview of a few basic techniques you can use to evaluate pages and users:
-
WMF Article Info Tool. This tool (run by the Wikimedia Foundation, Wikipedia’s parent) provides detailed information on any Wikipedia page, from articles to user pages to user talk pages. It shows the breakdown of editors by both number of edits and content added, the page’s traffic analytics (which is otherwise only easily accessible via Wikipedia’s API), and other useful statistical breakdowns.
-
WMF Global User Contributions. This site provides a history of all the edits made by a particular user across all Wikimedia platforms — be they English Wikipedia (“enwiki”), Wikimedia Commons (where images are stored), or any other WMF-run Wiki.
-
WFM Blame. Given a page and some text on that page, this tool shows you which user added or edited that text. This tool can be very helpful when assessing how controversies appear on a page.
-
Other WFM tools. The tools listed above were the ones we found most useful, but several other analysis tools are also available on this page.
-
Pageview comparer. This tool allows you to compare the pageview history of multiple pages on the same graph. It can be useful for detecting spikes of activity (which may be correlated with major events).
-
WikiSHARK. This tool allows you to visualize page views for the years 2008-2020. It can be useful for identifying trends in traffic.
-
Basic edit histories. To view the edit history of a page, click the “View history” button on the top right of any Wikipedia page (including user pages and talk pages). From there, you will see a chronological list of edits, showing the size, user, and associated message of each edit. To see the changes made in any edit, click the “prev” button. You can also compare across multiple edits using the select buttons on the left.
-
Talk pages. Talk pages are where editors talk about a page. Articles’ talk pages usually contain discussion on whether to include certain information in a page, whether the subject of a page is notable enough to warrant an article on Wikipedia, and how a page should be written. When investigating an article, always read its talk page. (Here is Kamala Harris’ talk page.)
Automated Analysis
With more than six million pages, Wikipedia is vast. Unless your investigation is focused only on a single subject, there are likely far more pages than you can hope to look through and assess manually. To solve this problem of scale, we built two systems to help seed investigations.
The first tool, our open-source Wikipedia Scanner, is a Python notebook that intakes a search query and analyzes each page that matches the query. It then outputs a number of charts about the collection of pages it found, as well as anomalous pages it thinks might warrant further manual investigation.
When looking for anomalous pages, it considers the edits-to-pageview ratio, the length-to-pageview ratio, and the editors-per-edit ratio, among other metrics. While not every page it finds is ultimately suspicious, it can be very helpful for seeding deeper investigations.
No programming is required to use the tool — just type your search query into the box at the top right, then click “Runtime” then “Run all” (or “Restart and run all”). Include “incategory:living_people” to filter your results to biographical pages. (Unlike many other categories on Wikipedia, the “living people” category has almost perfect coverage; if a page corresponds to a living person, it almost certainly is in the category, and vice versa.)
As a proof-of-concept for how the Wikipedia Scanner can be used to seed investigations, we searched for the exact phrase “serving as the U.S. Representative” (to select for pages using the standard format for members of the US House of Representatives) within the category of living people ("incategory:living_people"). We then filtered by highest edits to pageview ratio to identify controversial or vulnerable topics.
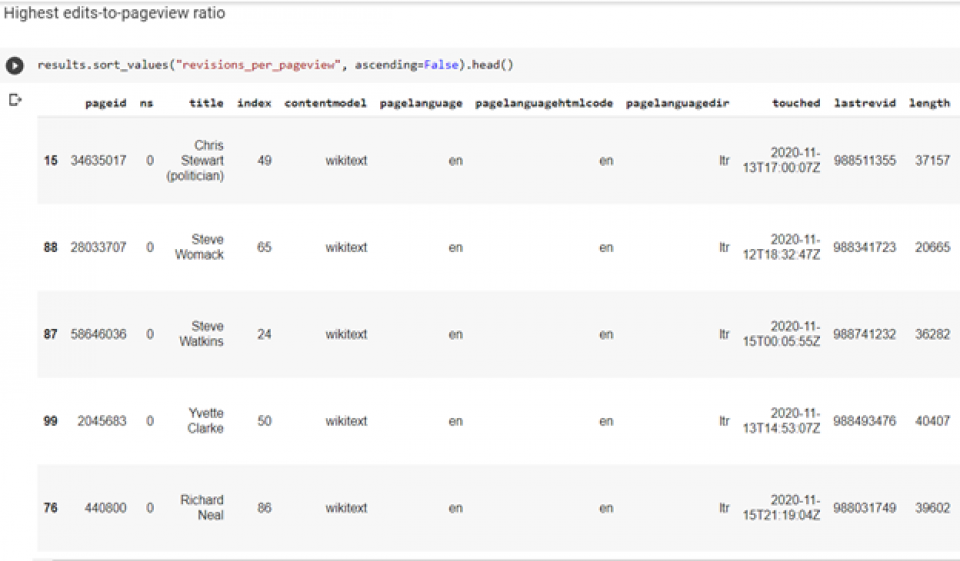 A screenshot of the analysis script outputting results for the U.S. Representative query.
A screenshot of the analysis script outputting results for the U.S. Representative query.
The top five results were Chris Stewart, R-Utah, Steve Womack, R-Ark., Steve Watkins, R-Kan., Yvette Clarke, D-N.Y., and Richard Neal, D-Mass. Of the five, at least four had unusual edits in their history:
- Steve Womack
The most documented of these pages’ histories is Steve Womack. His legislative record was covered on Last Week Tonight with John Oliver in 2015, and in the few days after the show aired his page was vandalized over a hundred times, referencing his relationship with Tyson Foods and chickens. Although his page was subject to a mass editing attempt (albeit uncoordinated), it is largely a Wikipedia editing success story: ultimately, the vandalism was held back successfully. - Yvette Clarke
The controversy around Yvette Clarke dates back to a statement that she made on the Colbert Report in 2012 about there being slavery in New York in 1898, as well as an earlier controversy around whether or not she graduated from Oberlin College. The talk page shows that, at one point in time, the controversy around her graduation was entirely removed, and her appearance on the Colbert Report was characterized as ‘joking.’ WFM Blame establishes that the user only made edits to Clarke’s page. These edits—which clearly cast Clarke in a better light—were performed without consensus, noticed, and reverted. - Steve Watkins
Steve Watkins is another case of a Wikipedia page that had controversy significant enough to be notable beyond Wikipedia. The talk page documents Watkins editing the page himself and commenting, “I am Steve Watkins. My lawyers and I edited this page because it was heavily biased.” His efforts to remove negative parts of the page were mentioned in the Kansas City Star. - Richard Neal
Richard Neal has an uncontroversial talk page, though there is some concern about a number of instances of positive language that trace back to a single editor, Designate, who is responsible for writing 52.4% of the page. Designate’s edits include ambiguous positive statements, including that Neal “had a hand” in the financing plans for the ACA, that he made economic policy “the focus of his career,” that he oversaw a period of unprecedented economic growth when he was mayor, and that Neal “won several acclamations” for maintaining American involvement in the peace process in Northern Ireland. - Chris Stewart
Chris Stewart also has an uncontroversial talk page, and the edit history appears uncontentious. The high edit-to-pageview ratio could be explained by his divisiveness as a political figure.
Our second tool was a script that collected bulk data from Wikipedia articles that used the “officeholder” template (i.e. most politicians). It iterated over the first 10,000 pages and exported the metrics described above to a .csv file. By analyzing the exported data in Excel, we were able to identify pages with low traffic but suspiciously-high numbers of edits. These pages are often worthy of deeper scrutiny. Although it would not be suitable for smaller area-specific investigations, the bulk data was very useful in identifying leads. We discovered several suspicious pages using this script.
Note: The Wikipedia API imposes a one-per-second limit on collecting page data, so iterating through all 10,000 pages (the maximum amount returned by the API) takes hours to complete.
- Ranjith Bandara
The page of Sri Lankan Member of Parliament Ranjith Bandara was edited 32 times between November 17, 2020 and December 17, 2020, despite getting only 499 views. A look at its history reveals that two anonymous users with the names “DKB1997” and “Ranga94” repeatedly attempted to add around 17,000 characters worth of content to the page that lists his board positions, research, awards, publications and more. The edits also included the line “[he] has two sons Dhananjaya and Kanishka Bandara.” A look at “happy birthday” posts on Ranjith Bandara’s Facebook page reveals that his two sons Kanishka and Dhanajaya were born in 1997 and 1994 respectively. The birth years match up with the numbers in the usernames, and the “KB” in “DKB1997” may be his son Kanishka’s initials. While we have no way to verify the identities of the users, it is likely that only Ranjith Bandara himself or someone very close to him could have such an intimate knowledge of his past and achievements. - Kevin Parker
The page of New York State Senator Kevin Parker was edited 34 times in October 2020, despite getting only 825 views. A look at its revision history reveals that anonymous users with the IP addresses “24.29.56.240” and “198.163.154.240” made dozens of edits to sections titled “Controversies, altercations, and legal troubles,” “Conviction of misdemeanor felony mischief,” and “Tirades.” The former attempted to add content to these sections and the latter attempted to remove content from them, calling it “libel” in one revision. A reverse search of the “24.29.56.240” IP address reveals it is located in Albany, the state capital of New York. A reverse search of the “198.163.154.240” IP address reveals it is owned by the New York State Senate itself. This suggests that the two anonymous users are involved with Kevin Parker politically, in one way or another, and that there may be foul play involved. - Alfred-Maurice de Zayas
The page of Cuban-American human rights researcher and United Nations Independent Expert Alfred-Maurice de Zayas is more than 11,265 words long, despite getting only 1,431 views in October. This is more than 10 times the length of similar pages. A look at the revision history reveals that an editor with the username “CubaHavana2018” has been regularly contributing to the page since early 2019, filling out lengthy sections about the subject's books, UN reports, activism, awards and more. A look at the user’s history reveals that it has only made contributions to Zayas’ page, and its “CubaHavana2018” name raises suspicions because de Zayas himself was born in Havana. While we have no way to verify the user’s identity, most of the information they added is detailed and personal and it appears that only de Zayas himself or someone very close to him could be so intimately familiar with his past. It appears that editors noticed the suspicious activity back in November 2016, adding a warning to the top of the page that “a major contributor to this article appears to have a close connection with its subject.” Despite the disclaimer, the edits have continued.

The Bottom Line
Wikipedia is a joy to investigate: because there is no adversarial relationship between the researcher and the platform, there are dozens of tools available to help along the way. Access to the internals of Wikipedia is unparalleled relative to other platforms. Despite this openness, inauthentic behavior still slips through the cracks. The tools described in this guide, combined with investigatory creativity and intuition, will take you as far as you need to go. As a platform, Wikipedia stands beside you — not in your way.


